



 전체상품검색
전체상품검색How To Save Money With Deepseek?
페이지 정보
작성자 Joan Behrend 댓글 0건 조회 7회 작성일 25-02-19 00:40본문
We will iterate this as a lot as we like, although DeepSeek v3 solely predicts two tokens out during training. This implies the model can have extra parameters than it activates for every specific token, in a way decoupling how much the model knows from the arithmetic value of processing individual tokens. While the full start-to-finish spend and hardware used to construct DeepSeek could also be greater than what the corporate claims, there may be little doubt that the mannequin represents an incredible breakthrough in coaching effectivity. However, when our neural network is so discontinuous in its habits, even the high dimensionality of the problem space may not save us from failure. The two projects talked about above reveal that attention-grabbing work on reasoning fashions is possible even with restricted budgets. Give DeepSeek Ai Chat-R1 models a attempt at this time in the Amazon Bedrock console, Amazon SageMaker AI console, and Amazon EC2 console, and ship suggestions to AWS re:Post for Amazon Bedrock and AWS re:Post for SageMaker AI or by way of your traditional AWS Support contacts. From the AWS Inferentia and Trainium tab, copy the example code for deploy DeepSeek-R1-Distill fashions. To learn more, seek advice from this step-by-step information on how one can deploy DeepSeek-R1-Distill Llama fashions on AWS Inferentia and Trainium.
 Today, now you can deploy DeepSeek-R1 models in Amazon Bedrock and Amazon SageMaker AI. Now you can use guardrails without invoking FMs, which opens the door to more integration of standardized and thoroughly examined enterprise safeguards to your software circulation regardless of the models used. ChatGPT is extra mature, whereas DeepSeek builds a cutting-edge forte of AI applications. 3. Could DeepSeek act in its place for ChatGPT? DeepSeek Explained: What is It and Is It Safe To use? As like Bedrock Marketpalce, you should use the ApplyGuardrail API within the SageMaker JumpStart to decouple safeguards to your generative AI applications from the DeepSeek-R1 model. Using DeepSeek-V2 Base/Chat models is topic to the Model License. Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd., doing business as DeepSeek, is a Chinese synthetic intelligence company that develops open-supply massive language fashions (LLMs). Rewardbench: Evaluating reward fashions for language modeling. One of the most outstanding features of this launch is that DeepSeek is working utterly within the open, publishing their methodology intimately and making all DeepSeek fashions accessible to the global open-supply group.
Today, now you can deploy DeepSeek-R1 models in Amazon Bedrock and Amazon SageMaker AI. Now you can use guardrails without invoking FMs, which opens the door to more integration of standardized and thoroughly examined enterprise safeguards to your software circulation regardless of the models used. ChatGPT is extra mature, whereas DeepSeek builds a cutting-edge forte of AI applications. 3. Could DeepSeek act in its place for ChatGPT? DeepSeek Explained: What is It and Is It Safe To use? As like Bedrock Marketpalce, you should use the ApplyGuardrail API within the SageMaker JumpStart to decouple safeguards to your generative AI applications from the DeepSeek-R1 model. Using DeepSeek-V2 Base/Chat models is topic to the Model License. Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd., doing business as DeepSeek, is a Chinese synthetic intelligence company that develops open-supply massive language fashions (LLMs). Rewardbench: Evaluating reward fashions for language modeling. One of the most outstanding features of this launch is that DeepSeek is working utterly within the open, publishing their methodology intimately and making all DeepSeek fashions accessible to the global open-supply group.
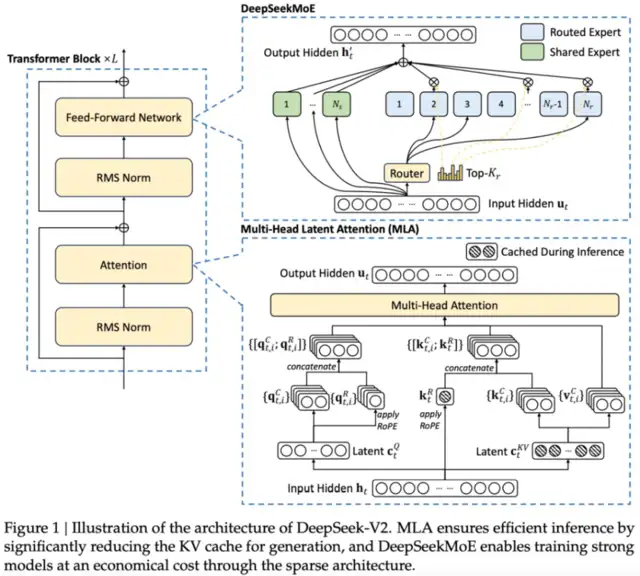
This rough calculation shows why it’s essential to seek out ways to scale back the dimensions of the KV cache when we’re working with context lengths of 100K or above. From my initial, unscientific, unsystematic explorations with it, it’s really good. It’s not just sharing leisure movies. The newest model, DeepSeek-V2, has undergone significant optimizations in architecture and efficiency, with a 42.5% discount in training prices and a 93.3% reduction in inference costs. Compared with DeepSeek 67B, DeepSeek-V2 achieves stronger efficiency, and in the meantime saves 42.5% of training costs, reduces the KV cache by 93.3%, and boosts the maximum era throughput to 5.76 occasions. FP8-LM: Training FP8 large language models. By intently monitoring both buyer needs and technological advancements, AWS usually expands our curated choice of models to incorporate promising new fashions alongside established business favorites. You can deploy the DeepSeek-R1-Distill fashions on AWS Trainuim1 or AWS Inferentia2 instances to get the perfect value-efficiency.
DeepSeek refers to a brand new set of frontier AI fashions from a Chinese startup of the identical title. The unique V1 model was educated from scratch on 2T tokens, with a composition of 87% code and 13% pure language in both English and Chinese. We present DeepSeek-V3, a robust Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. LLaMA: Open and efficient foundation language fashions. To entry the DeepSeek-R1 model in Amazon Bedrock Marketplace, go to the Amazon Bedrock console and choose Model catalog underneath the foundation models section. Here, one other firm has optimized DeepSeek's models to scale back their costs even additional. In theory, this might even have helpful regularizing results on training, and DeepSeek reviews finding such results in their technical studies. People are utilizing generative AI systems for spell-checking, research and even extremely private queries and conversations. Methods reminiscent of grouped-question attention exploit the possibility of the identical overlap, however they accomplish that ineffectively by forcing consideration heads that are grouped collectively to all respond similarly to queries. For instance, GPT-three had 96 attention heads with 128 dimensions each and 96 blocks, so for every token we’d need a KV cache of 2.36M parameters, or 4.7 MB at a precision of 2 bytes per KV cache parameter.
- 이전글Hidden Answers To Deepseek Ai Revealed 25.02.19
- 다음글The Do's and Don'ts Of Watch Free Poker TV Shows 25.02.19
댓글목록
등록된 댓글이 없습니다.





